
Predictive Analytics, Implementation Science, Precision Medicine and Precision Public Health
Posted on by This blog is a summary of our recent paper based on a multidisciplinary workshop convened by the National Heart, Lung, and Blood Institute to explore enhancement of predictive analytics for implementation research. The use of predictive analytics in precision medicine (the right intervention to the right patient at the right time) is well established. The more recent development of precision public health (the right intervention to the right population at the right time) identifies needs for predictive analytics similar to the field of precision medicine.
This blog is a summary of our recent paper based on a multidisciplinary workshop convened by the National Heart, Lung, and Blood Institute to explore enhancement of predictive analytics for implementation research. The use of predictive analytics in precision medicine (the right intervention to the right patient at the right time) is well established. The more recent development of precision public health (the right intervention to the right population at the right time) identifies needs for predictive analytics similar to the field of precision medicine.
The Domains of Data For Precision Medicine and Precision Public Health
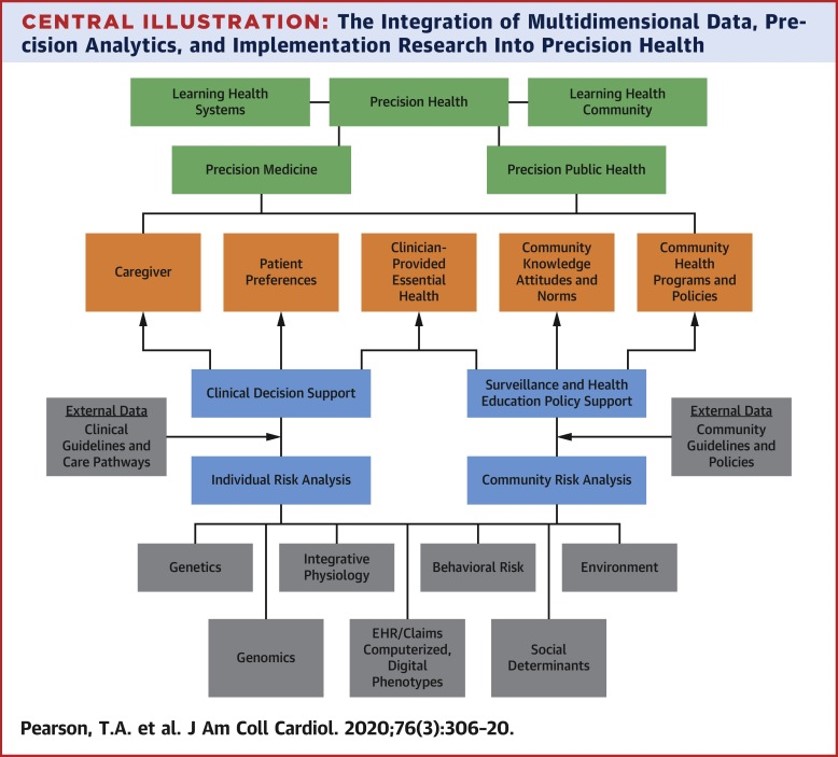
At least five domains of data sources exist that can affect human health: medical/health care, genetics/genomics/integrative biology, behaviors, social factors, and the physical and social environment. There is increasing interest not only in genetics/genomics, but also in behavioral medicine and the role of social and environmental determinants of health. The inclusion of multiple domains has rapidly expanded the digital information available for each individual (Figure). In the future, information will also include a full metabolomics profile, transcriptomics, epigenomics, and integrative systems biology, measuring the interaction of human systems from cells to organ systems. Additionally, large increases in digital information describing social correlates and determinants of health and the physical setting in which patients live. Digital phenotyping from mobile and other personal devices for continuous or intermittent physiological monitoring will passively quantify human behaviors, physiologic responses, and environmental exposures.
Four critical areas were explored by workshop participants as necessary to foster progress in predictive analytics for improving individual and population health, with a focus on heart, lung, blood and sleep disorders. Each workshop goal was addressed with presentations and included a use-case, which provided a salient example of ongoing programs.
Goal 1: Identify, manage, organize, and make accessible diverse types of information/data at scales appropriate to broad populations
Ideally, to transform this information into actionable knowledge, data need to be meaningful, valid, accurate, reliable, comprehensive, representative, accessible, reproducible, and collected repeatedly over time. To be actionable, the predictive analytic models need to be valid, usable and integrated into workflows in ways that support and enhance the effectiveness of various healthcare organizations and communities/sub-populations. For example, the decision-making needs of communities (e.g. neighborhoods, school districts, work sites, etc.) and geopolitical areas (e.g. counties, cities, states, etc.) are at the population level. The individuals’ information can be aggregated into geographic data to describe that population’s health, or the community’s information can be an index of an individual’s exposome. Similarly, data that characterize a community’s social capital, levels of social deprivation, diverse environmental exposures, and clinical and public health resources can be important parts of the community’s exposome.
Goal 2. Develop and Apply Methods of Data Science to Assess Determinants of Health and Prediction of Outcomes at the Individual Person and Community Levels
The application of data science to the large and complex information relevant to both individual and community health must address several challenges. The first challenge is integration with large data elements from various sources, different data structures, and unstandardized contents in relation to their meaning. Another challenge is to synthesize data from various study designs, including cross-sectional, case-control, and longitudinal cohort designs. Predictive analytics use statistical and machine learning models to predict outcomes from observational data. Some of the models can be used to select a subset of variables that are strongly associated with an outcome of interest, and such models can be useful for discovery or hypothesis-testing. However, predictive models are not necessarily causal models. Statistical learning and visualization could enable development of clinical decision support tools for individual care. A parallel but similar analysis might be used in communities, especially using geospatial modeling to define the population described. While population-wide genomic testing is not yet available, other clinical data such as computerized case definitions could be used to identify outbreaks of acute illnesses, clusters of chronic diseases, or events corresponding to rapid disease progression in time and place. Decision support tool for communities would then identify a geospatial population with a health burden, characterize its social, behavioral, environmental and clinical characteristics, and construct an initial, data-driven strategy to mitigate the disparity in disease burden.
Goal 3. Apply and Evaluate Novel Tools and Programs to Reduce Harm and Cost and Improve Predictive Accuracy in Clinical Care and Community-based Programs
Predictive Analytics can lead to improved risk assessment, better definition of disease subgroups with differing pathophysiology and natural history, and more precise use of therapeutics to maximize benefits and minimize side effects. For individual patients, before decision support tools derived from complex analytics are widely deployed, they should be implemented in a structured manner, and the benefits and risks should be measured. Similar challenges would be faced by implementation of community interventions, in which surveillance, health education, community organization, environmental change, or public policy interventions should be rigorously evaluated for degree of implementation as well as health outcomes. Predictive analytics can inform options and aid the decisions about clinic location and the healthcare services to be provided.
Goal 4. Advance the Quality, Quantity and Diversity of the Data Science Workforce and the Data Science “Savviness’ of the Healthcare and Public Health Workforces
A critical workforce shortage in the quantitative sciences and in the application of mathematics to life sciences and healthcare currently exists. With the advent of large amounts of complex data from numerous domains, there are far too few people with the necessary competencies to manage the data and too few quantitative scientists with advanced expertise to create new approaches to the development of algorithms. Commensurate with rapidly emerging data complexities, the expansion of the data science workforce should particularly focus on precision analytics and their integration with research programs performing clinical and population research.
Implications for Implementation Science
Implementation science increasingly recognizes the role of social and physical contexts in which the clinical and public health interventions and their outcomes may be studied. Community studies also require individuals’ characteristics and summary measures that describe the health of the population in which the implementation research is being performed. Implementation science offers the evidence demonstrating the feasibility, effectiveness, and safety of the precision analytic-based intervention, the individual or population level of the intervention in which it is effective, and characteristics of the intervention that are related to its effectiveness.
* This blog acknowledges the work of the NHLBI workshop participants as reported in Pearson TA, et al. Precision Health Analytics With Predictive Analytics and Implementation Research: JACC State-of-the-Art Review. JACC 2020;76(3):306-320. For a full list of authors please refer to the workshop report at: https://pubmed.ncbi.nlm.nih.gov/32674794/
Posted on by